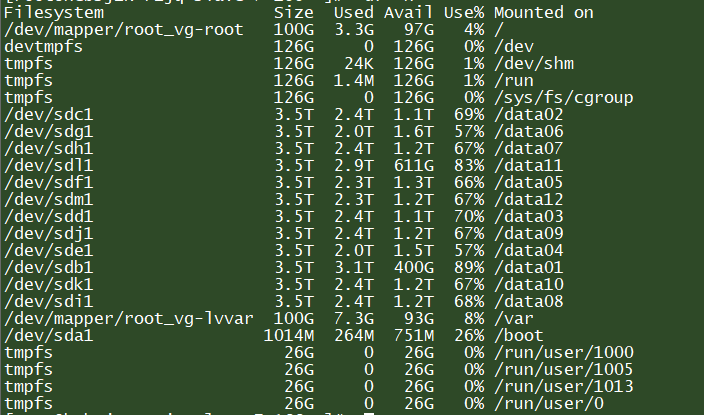
平时运维 Hadoop 集群时,会发现虽然整个集群的 DataNode 已经处于均衡状态,但是单个DataNode 节点的各个 disk 并不均衡。比如如下图所示。
那么如何配置使得一个 DataNode 的每个磁盘之间是均衡的。
默认情况下,DataNode 仅循环地将新的块副本写入磁盘卷。但是我们可以配置一种(磁盘)卷选择策略,该策略使DataNode在决定放置新副本的位置时考虑每个卷上的可用空间。
可以在以下两个方面进行配置:
- 当每个磁盘可用空间差多少字节时,认为这个节点磁盘间是不均衡的;
- 空间更大的磁盘分配多少百分比的新数据块;
具体是以下几个配置项,如果没有,请新增。
| 参数 | 值 | 描述 |
|---|---|---|
| dfs.datanode. fsdataset. volume.choosing. policy | org.apache.hadoop. hdfs.server.datanode. fsdataset. AvailableSpaceVolumeChoosingPolicy | 在DataNode的磁盘之间实现存储平衡 |
| dfs.datanode. available-space- volume-choosing- policy.balanced- space-threshold | 10737418240 (default) | 相差多少时认为不均衡,默认10GB。 The amount by which volumes are allowed to differ from each other in terms of bytes of free disk space before they are considered imbalanced. The default is 10737418240 (10 GB). If the free space on each volume is within this range of the other volumes, the volumes will be considered balanced and block assignments will be done on a pure round-robin basis. |
| dfs.datanode. available-space- volume-choosing- policy.balanced- space-preference-fraction | 0.75 (default) | 空间较大的磁盘分配新块的百分比,应当配置在0.5以上,1.0以下。 What proportion of new block allocations will be sent to volumes with more available disk space than others. The allowable range is 0.0-1.0, but set it in the range 0.5 - 1.0 (that is, 50-100%), since there should be no reason to prefer that volumes with less available disk space receive more block allocations. |
保存之后,重启相应服务。
Refer: cloudera doc