使用 ambari 来搭建 hdp 集群,前前后后搭了不下10遍,之前一直没有完整的总结整个过程,最近有空正好记录一下。
什么是Ambari?
简单来说:Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是顶级项目。 这句话基本等于是一句废话。以下是官网的解释: The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs. 这里是Ambari官网:http://ambari.apache.org/
也就是说:Ambari是一个可以用来简化Hadoop集群创建、管理、监控的一个软件。今天就来介绍如何安装Ambari和如何使用Ambari来部署Hadoop集群。
对于HDP集群,ambari是一个极其优秀的管理软件。本文就来介绍,如何使用ambari来部署一个HDP集群。
环境准备
-
准备至少3个节点
-
配置好节点免密登陆
# ssh-keygen -t rsa ... # ssh-copy-id root@$nodes -
设置好主机名及hosts文件
-
设置好系统时区及时钟同步(ntp)
timedatectl status timedatectl set-timezone Asia/Shanghai -
关闭防火墙
sudo systemctl stop firewalld sudo systemctl disable firewalld -
关闭selinux
getenforce setenforce 0 vim /etc/selinux/conf SELINUX=disabled -
安装好JDK
#下载tar包 http://www.oracle.com/technetwork/java/javase/downloads/index.html #解压到指定目录 tar -zvxf jdk...tar.gz -C /cm/jdk mv /cm/jdk/jdk.1.8.xxx . #修改环境变量 打开/etc/profile文件 vi /etc/profile 在最后添加 export JAVA_HOME=/cm/jdk export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$JAVA_HOME/bin:$PATH 保存退出后,执行source /etc/profile是修改的环境变量生效 -
umask设置
sudo vim /etc/profile umask 0022 source /etc/profile -
关闭linux swap
vim /etc/sysctl.conf 在最后添加: vm.swappiness=0至此,操作系统设置差不多完成。
配置yum源
需要注意,根据不同的版本需求选择不同的版本进行配置。
- 如果你的机器可以连接外网
将对应的ambari版本的repo文件下载下来:
wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.0.1/ambari.repo
我装的是2.0.1版本的,追求高版本的同学可直接把上面2.0.1改为自己想要的版本,比如:2.5.2,有哪些版本可到官网上查看。
将下载的 ambari.repo 文件拷贝到 Linux 的系统目录/etc/yum.repos.d/。拷贝完后,我们需要获取该公共库的所有的源文件列表。依次执行以下命令。
yum clean all;yum makecache
yum list|grep ambari
这样便可以了。
- 如果你是内网机器
在这些地址下载Ambari与HDP的相关安装包文件,选择需要的版本下载,并检验其MD5值。 http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari-2.4.2.0-centos7.tar.gz
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari-2.4.2.0-centos7.tar.gz.md5
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.5.3.0/HDP-2.5.3.0-centos7-rpm.tar.gz
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.5.3.0/HDP-2.5.3.0-centos7-rpm.tar.gz.md5
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz.md5
选择一台主机作为yum源主机,配置集群yum源。
-
安装httpd
sudo yum -y install httpd sudo systemctl start httpd sudo systemctl enable httpd
解压下载的tarball到目录/var/www/html,参考命令:
tar -xzvf ambari-2.4.2.0-centos7.tar.gz -C /var/www/html
tar -xzvf HDP-2.5.3.0-centos7-rpm.tar.gz -C /var/www/html
tar -xzvf HDP-UTILS-1.1.0.21-centos7.tar.gz -C /var/www/html
登录Ambari服务节点,新建配置文件/etc/yum.repos.d/ambari.repo,并填入以下内容:
[ambari-2.4.2.0]
name=ambari-2.4.2.0 - Updates
baseurl=http://192.168.xx.xx/AMBARI-2.4.2.0/centos7/2.4.2.0-136
gpgcheck=1
gpgkey=http://192.168.xx.xx/AMBARI-2.4.2.0/centos7/2.4.2.0-136/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
同样的方法设置hdp源。
安装Ambari
1、如果选择将Ambari server安装在这台机器上,则:
yum install ambari-server
2、配置ambari-server
ambari-server setup
这是一个交互环境,记住:
在选择database时,选择内嵌数据库,也就是 Postgres 数据库。 如果需要。 默认会安装并使用 Oracle 的 JDK,但是建议选择custom,然后填入你的jdk地址即可,这样会快很多,因为无需下载jdk 指定 Ambari Server 的运行用户为 root 其他配置均使用默认,即可以直接回车。
3、启动ambari server
ambari-server start
成功启动 Ambari Server 之后,便可以从浏览器登录,默认的端口为 8080。以我的环境为例,在浏览器的地址栏输入 http://hdp1:8080,登录密码为 admin/admin。登入 Ambari 之后的页面如下图。
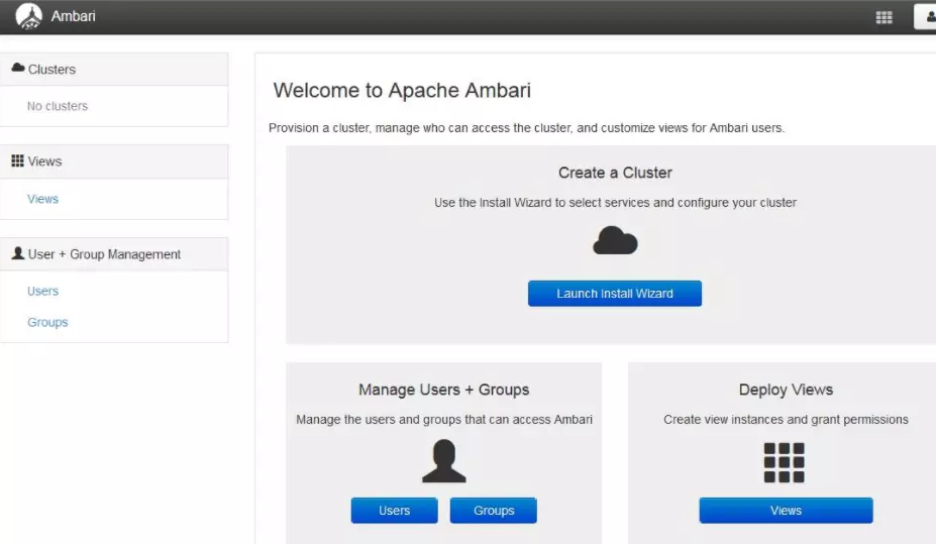
部署HDP集群
1、点击上述图片中的Launch install Wizard
2、选择stack 我选择 的是HDP2.2,里面的对应的 Hadoop 版本为 2.6.x
3、指定 Agent 机器(如果配置了域,必须包含完整域名,例如本文环境的域为 example.com),这些机器会被安装 Hadoop 等软件包。配置SSH免密登陆时,会生成一个rsa_id文件,也就是私钥,这里需要指定当时在 Ambari Server 机器生成的私钥。
cat /root/.ssh/rsa_id
把输出内容粘贴到这个文本框即可。
4、confirm hosts 也就是安装向目的主机安装ambari agent,一行写一台主机,填写是要主要填写主机主机名,不要填写IP,要不然有可能出现以下错误:
ambari agent machine hostname (node11) does not match expected ambari server hostname (192.168.XX.XX).
这是因为ambari-agent 在注册时,默认会获取主机主机名,并使用主机名想ambari-server注册。
5、choose service 选择你要安装的服务,我这里选择: HDFS、Yarn、zookeeper、HBase
6、Assign master和slave 即:分配哪些机器安装哪些服务
下面步骤都很简单,一直点击next便可完成。
安装完之后便可以得到图示结果:
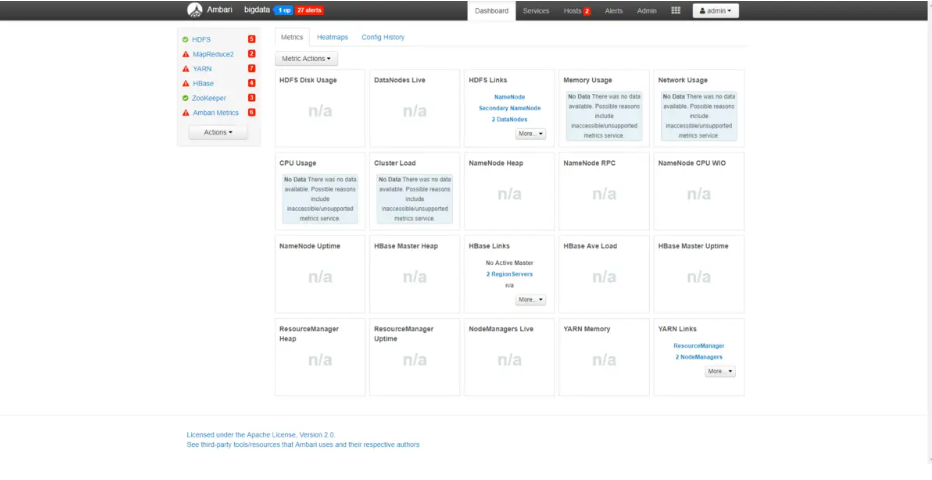
刚装好时,因为所有服务都没启动,所有全是告警,上图因为我正在启动服务,所有欧HDFS和zookeeper显示无告警。
7、点击上图Actions »start all 。启动所有服务。
遇到的错误
- ambari-agent无法向ambari-server注册
Registering with the server...
Registration with the server failed.
If the output says openssl-1.0.1e-15.x86_64 (1.0.1 build 15) you will need to upgrade the OpenSSL library by running the following command:
更新下openssl后恢复
#yum update openssl
- ResourceManager无法启动
查看resourcemanager日志:/var/log/hadoop-yarn/yarn/yarn-yarn-resourcemanager.log,发现如下报错:
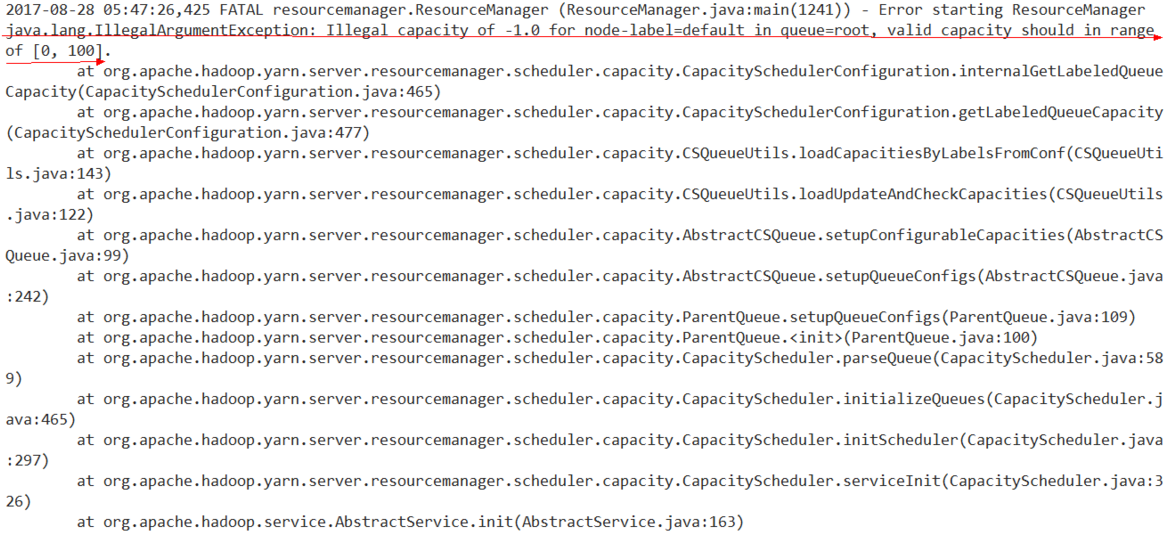 可以看出 Illegal capacity of -1.0 for node-label=default 为罪魁祸首,在ambari找到node-label相应参数:
可以看出 Illegal capacity of -1.0 for node-label=default 为罪魁祸首,在ambari找到node-label相应参数:

将两个-1修改为1即可:

保存,若提示内存不够,点proceed anyway即可,重启生效。 即可。
- zookeeper无法启动
查看zookeeper.out 日志
[myid:3] - INFO [main:FileSnap@83] - Reading log /hadoop/zookeeper/version-2/log.10000000
[myid:3] - ERROR [main:Util@239] - Last transaction was partial.
[myid:3] - ERROR [main:QuorumPeer@648] - Unable to load database on disk
后面还报了cannot access /hadoop/zookeeper/version-2/ 什么的,记不得了。遂查看/hadoop/zookeeper/version-2/目录权限。
查看该文件权限
[root@node12 zookeeper]# ll /hadoop/zookeeper/
total 4
-rw-r--r-- 1 root root 1 Dec 2 10:50 myid
drwxr-x--- 2 zookeeper hadoop 68 Dec 1 16:48 version-2
[root@node12 zookeeper]# ll /hadoop/zookeeper/version-2/
total 580
-rw-r----- 1 root root 1 Dec 1 16:48 acceptedEpoch
-rw-r----- 1 root root 1 Dec 1 16:48 currentEpoch
-rw-r----- 1 root root 67108880 Dec 1 18:15 log.10000000
修改文件权限
chown -R zookeeper:hadoop /hadoop/zookeeper/version-2/
重启即可。
试跑
一切无恙之后,跑一个MR试试 ![]()
[hdfs@node01 ~]$ hadoop jar /usr/hdp/2.2.9.0-3393/hadoop-mapreduce/hadoop-mapreduce-examples-2.6.0.2.2.9.0-3393.jar pi 3 100
能正确跑完即正常。
对于使用ambari安装Hive等组件,下一篇文章再讲。